





- 252 高校采购信息
- 616 科技成果项目
- 10 创新创业项目
- 0 高校项目需求
人工智能大模型的高性能加速系统


1. 痛点问题
大模型的发展已成为人工智能领域的一个重要趋势,其具有更强的表达能力和更高的准确性,可以帮助人类解决更复杂的实际问题。然而,大模型的训练面临巨大的计算压力。主流的大模型参数量已达到TB量级,必然需要使用分布式系统进行处理,通过将模型和数据分配到多个计算设备上进行并行计算,从而提高训练速度。但是,分布式训练的成本非常高昂,需要使用大量高性能的计算设备,而这些设备的价格居高不下,甚至在市场上难以获得。
并行训练系统的性能优化是降低训练成本的重要手段。目前开源的分布式训练软件包括英伟达公司的 Megatron-LM和微软公司的 DeepSpeed 等。虽然这些框架可以在给定的硬件平台上对给定模型进行较好的并行训练支持,但还存在一些局限性:
(1)性能仍有提升空间。目前广泛使用的方案基于数据并行,通信量巨大,并行效率低下;
(2)依赖并行专家进行调优。现有系统提供了更多混合的并行方式的选择,在数量众多的可行的并行方案中选择最优的并行方案是十分困难的,而任意选择的并行方案可能会花费数倍于最优方案的时间;
(3)对于具有动态性的模型支持不足。现有的系统对于混合专家模型等具有动态负载特性的场景缺乏有效的处理机制,导致负载不均衡现象严重,从而导致训练效率低下;
(4)缺乏对于多种不同硬件平台的支持。目前主流的软件系统与英伟达公司的GPU硬件绑定程度较深,难以移植到其它硬件平台。
2. 解决方案
本技术成果包含以下核心技术点:(1)考虑硬件拓扑结构和性能特点的并行训练软件系统搭建与调优技术;(2)针对具有动态性的模型的高性能并行训练系统;(3)向国产算力系统移植并行训练系统的能力。
基于上述核心技术,本技术成果可支撑大模型并行训练解决方案。为有大模型训练需求的客户,如中小型企业、科研院校,提供高效的大模型并行训练资源。从超算中心、数据中心、云厂商等处获取大规模计算资源,并根据客户的需求部署效率最佳的并行训练软件系统,从而支持客户进行高效的大规模大模型分布式训练,降低大模型训练成本。
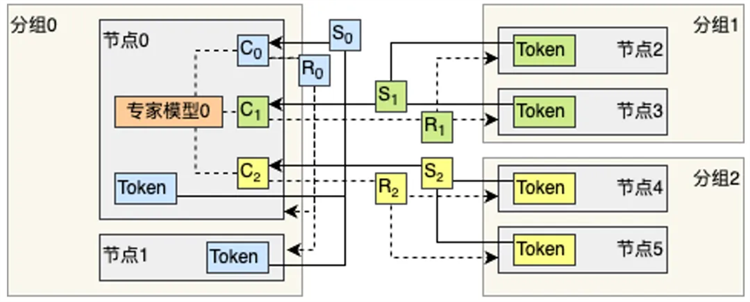
针对具有动态性的大模型的通信重叠调度机制
本项目拟先进行技术许可。
相比于已有的开源解决方案,本技术成果可提供针对不同硬件环境、目标模型规模,提供定制化并行性能调优,从而比选择默认并行配置获得更高的并行效率。例如针对混合专家模型,调优后的系统可获得超过十倍的效率提升,从而为客户节省更多成本。相比于专门雇佣并行专业人士的人力成本,使用统一的并行训练解决方案成本更低。

扫码关注,查看更多科技成果